TKK | Tietoverkkolaboratorio | Opetus
First, how would we define a search engine ? Usually search sites have been divided to two categories: directories and search engines. The difference between these categories is how the sites are structured. Directories have a highly structured system of categories to help users find sites whereas pure search engines offer no categorical structure at all - you can only use search form. Nowadays these differences are however disappearing. Web directories usually come equipped with their own keyword search engines that allow you to search through their indices for the information you need and several search engines are incorporating directories into their sites.
It seems that another difference between search sites, namely how search sites build and maintain their database indexes, would be better basis for classification. In directory sites indexing is usually done manually whereas search engines use web robots to index the Web. So we define search engine as a search site which employs web robot to index the Web.
What is web robot then ? Here is good definition for web robot by Martijn Koster:
"A robot is a program that automatically traverses the Web's hypertext structure by retrieving a document, and recursively retrieving all documents that are referenced. Note that "recursive" here doesn't limit the definition to any specific traversal algorithm; even if a robot applies some heuristic to the selection and order of documents to visit and spaces out requests over a long space of time, it is still a robot. Normal Web browsers are not robots, because the are operated by a human, and don't automatically retrieve referenced documents (other than inline images). Web robots are sometimes referred to as Web Wanderers, Web Crawlers, or Spiders. These names are a bit misleading as they give the impression the software itself moves between sites like a virus; this not the case, a robot simply visits sites by requesting documents from them."
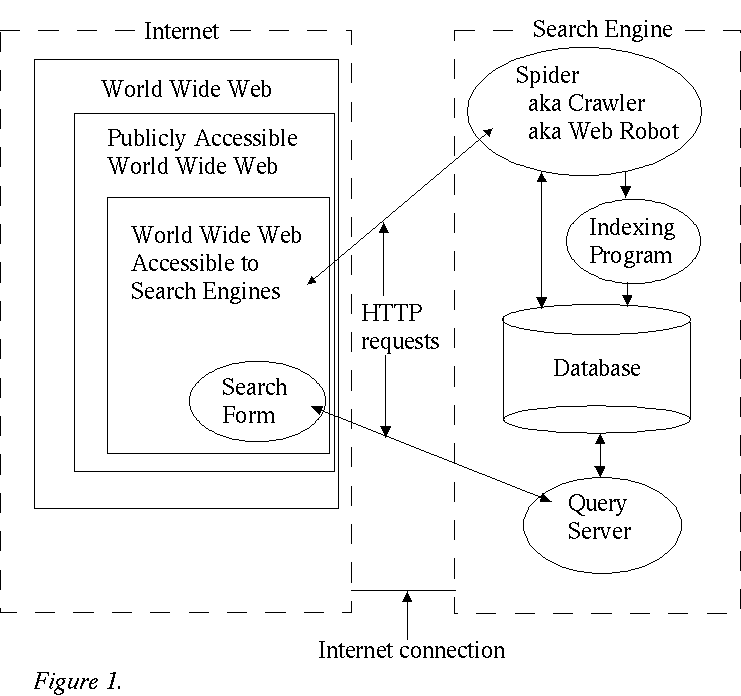
Now we could characterize search engine by saying that it uses web robot to crawl through the web and retrieve new documents and then index the contents of these documents to its database. In addition to indexing the web it also offers users a possibility to query its database. Based on this characterization we can divide a search engine to following functional parts:
[Previous page] [Contents] [Next page]