S-38.116 Teletietotekniikka
Seminaariesitelmä 3.4.1996
Timo Alakoski
35133C
Timo.Alakoski@hut.fi
Tietokonenäkö ja digitaalinen kuvankäsittely ovat aloja, joissa tarvitaan paljon laskentatehoa. Siirryttäessä fotogrammetriassa analogisista laitteista tietokonelaitteisiin ja digitaaliseen kuvankäsittelyyn on alalla kehitetty paljon monimutkaisia ja laskennallisesti raskaita algoritmeja, joiden ajamiseen tarvitaan tehokkaita koneita. Digitaalinen kuvankäsittely on toisaalta luonteeltaan hyvin rinnakkaiseen laskentaan soveltuvaa. Fotogrammetriassa rinnakkainen tai hajautettu laskenta onkin sen tähden erittäin houkuttelevaa. Fotogrammetrian ja kaukokartoituksen laboratoriossa on meneillään projekti, jossa tarkoituksena on muodostaa hajautetun laskennan järjestelmä, joka sopii erityisesti digitaalisen kuvankäsittelyyn liittyvien algoritmien laskemiseen.
Hajautettu laskenta ja rinnakkaislaskenta tarkoittavat yleisessä mielessä samaa asiaa. Hajautettu laskenta kuvaa ehkä paremmin järjestelmää, jossa prosessorit ovat fyysisesti erillään, esim. eri työasemissa jotka on lähiverkon kautta kytketty toisiinsa. Rinnakkaislaskenta mielletään enemmän tietokonejärjestelmään, jossa kaikki prosessorit ovat saman kuoren sisällä. Kummassakin tapauksessa arkkitehtuuri ja toiminta ovat samoja. Rinnakkaislaskennassa tehtävä hajautetaan usealle laskentaprosessorille samanaikaisesti suoritettavaksi siten, että kukin prosessori saa oman osatehtävänsä suoritettavakseen.
Rinnakkaislasketun ohjelman suoritusaika on pienempi kuin vastaavan ohjelman yksiprosessorijärjestelmässä. Rinnakkaislaskentaa voidaan myös käyttää ohjelmien ajamiseen, jotka muuten käyttäisivät suuria määriä keskusmuistia yksiprosessori-järjestelmässä. Hajautetulla laskennalla saavutetaan myös parempi vikasietoisuus, koska yhden prosessorin vaurio ei johda koko ohjelman kaatumiseen vaan hajautetussa järjestelmässä se aiheuttaa vain yhden osaprosessin kuolemiseen. Järjestelmän huomatessa tapahtuneen kyseinen osaprosessi delegoidaan muiden prosessien laskettavaksi.
Moniprosessorijärjestelmä on järjestelmä missä on on monta prosessoria. Monitietokone-järjestelmä on järjestelmä missä on monta tietokonetta. Koko tämän paperin käytetään sanaa prosessori, millä tarkoitetaan viittausta sekä moniprosessorijärjestelmiin että monitietokonejärjestelmiin.
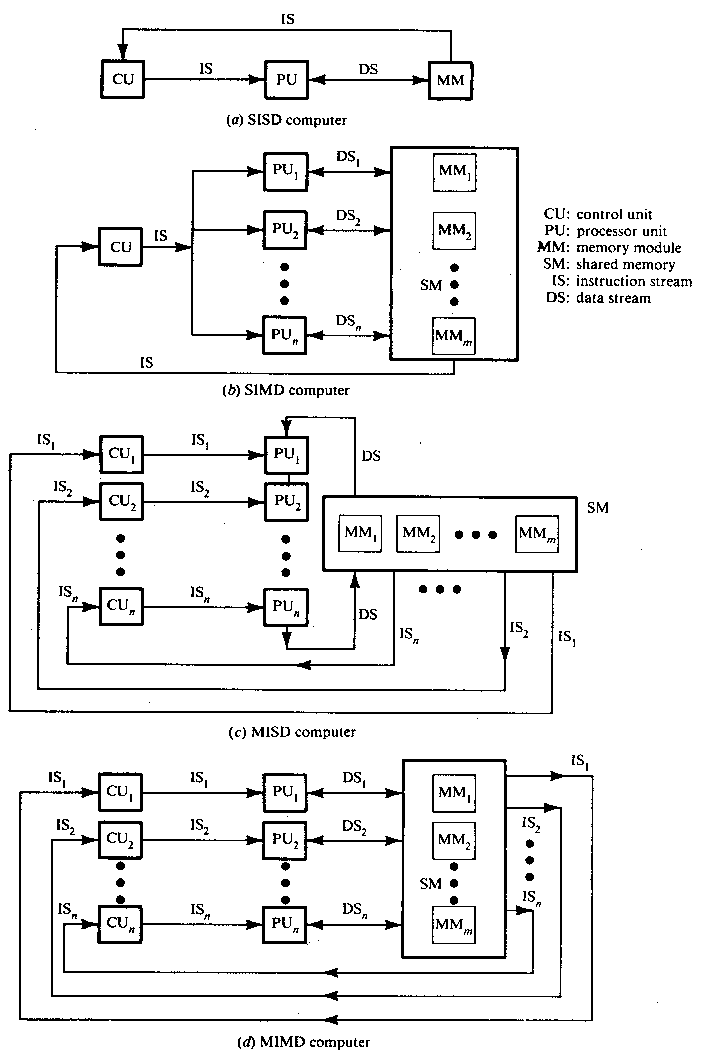
Tietokonejärjestelmät voidaan jakaa neljään luokkaa (ns. Flynnin luokittelu):
Perinteiset tietokoneet kuuluvat luokkaan SISD. Tässä mallissa on vain yksi prosessori, joka suorittaa vain yhden annetun käskyn kerrallaan yhdellä annetulla datan arvolla. Tähän ns. von Neumannin arkkitehtuuriin perustuvat kaikki nykyiset tietokoneemme. Kuvassa 1 esitetään Flynnin tietokonejärjestelmien luokkajako.
Kuva 1. Flynnin luokittelu eri tietokonejärjestelmille./1/
SIMD ja MIMD kuuluvat järjestelmiin, joissa operaatioita suorittavat monet prosessorit samanaikaisesti. Kummassakin järjestelmässä eri prosessorit saavat eri datan arvoja muistista. SIMD järjestelmässä kaikki prosessorit suorittavat samaa operaatiota eri datan arvoilla. Järjestelmässä on vain yksi kontrolleri, joka lukee ja välittää suoritettavat operaatiot ja datat prosessoreille. MIMD arkkitehtuurissa prosessorit suorittavat eri datoilla omia käskyjään. MIMD:ssä on jokaisella prosessorilla oma kontrollerinsa, joka huolehtii kyseiselle prosessorille annettavista käskyistä ja datoista. Harvinaisessa MISD arkkitehtuurissa prosessoreille annettaisiin eri käskyt mutta kaikille sama datan arvo. Tiettävästi kukaan ei ole valmistanut tämä arkkitehtuuria edustavaa konetta.
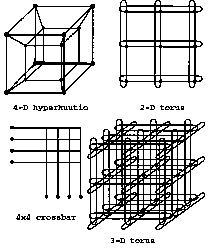
MIMD järjestelmät ovat todellisia moniprosessorijärjestelmiä. Järjestelmän prosessorit on kytketty toisiinsa viestintäkanavien avulla. Viestintäkanavina voivat toimia joko erilaiset tietoliikenneverkot tai jaettu muisti. Järjestelmiä, joissa prosessorit on kytketty toisiinsa tietoliikenneverkoilla sanotaan viestinvälitysjärjestelmiksi (message passing) tai hajautetun muistin järjestelmiksi (kuva 2a). Viestinvälitysjärjestelmissä jokaisella prosessorilla on tehtävänsä suorittamiseen oma muistinsa mihin muut prosessorit eivät pääse käsiksi. Prosessorit kommunikoivat keskenään tietoliikenneverkkojen välityksillä. Erilaisia topologioita verkkojen rakentamiseen on monia (kuva 2b).
Kuva 2a. Viestinvälitysjärjestelmä. b. Erilaisia verkkotopologia- ratkaisuja.
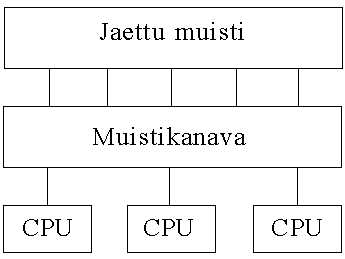
Kun käytetään jaettua muistia (shared memory) prosessorien väliseen yhteydenpitoon sanotaan järjestelmää jaetun muistin järjestelmäksi (kuva 3). Jaettu muisti voi olla joko keskitetty yhteen paikkaan tai hajautettu prosessoreille. Prosessorit käyttävät jaettua muistia kaikkeen prosessorien väliseen synkronisointiin ja kommunikointiin.
Kuva 3. Jaetun muistin järjestelmä.
Kummassakin järjestelmässä, sekä viestinvälitysjärjestelmässä että jaetun muistin järjestelmässä pullonkaulana on viestin kopioimiseen kulutettu aika suhteessa laskentatehoon. Tiedonvälitykseen kuluvaa aikaan voidaan yrittää pienentää suunnittelemalla tietoliikenneverkko mahdollisimman nopeaksi. Tämä on kuitenkin tapauskohtainen ja riippuu paljon ajettavasta algoritmista.
Digitaalisessa fotogrammetriassa on kuvien raskas käsittely hyvin yleistä. Tavallisia operaatioita ovat kuvan konvoluutio, erilaiset kuvien suodatukset (keskiarvo, mediaani ym.), kuvien tunnistukset jne. Kuvamateriaali voi vaihdella videokuvasta ilma- tai satelliittikuviin. Kuvien koot vaihtelevat muutamasta kymmenestä kilotavusta aina satoihin megatavuihin. Näillä voluumeilla algoritmien suorittaminen on hidasta työtä. Projektissa on tarkoitus saada aikaiseksi järjestelmä, jolla saadaan algoritmit laskettua nopeammin. Projektissa tehdyssä järjestelmässä on käytetty jaetun muistin arkkitehtuuria. Järjestelmästä on tarkoitus tehdä joustava ja ennenkaikkea sen pitäisi olla mahdollisimman yksinkertainen loppukäyttäjille.
Perinteinen ratkaisu jaetun muistin arkkitehtuurissa on käyttää väylää johon ovat kiinnittyneet kaikki prosessorit sekä jaettu muisti. Muisti on keskitetty yhteen paikkaan. Ongelma tässäkin tapauksessa on väylän hitaus. Prosessorien laskentanopeus on aivan eri suuruusluokkaa kuin väylän siirtonopeus. Jos väylään on kytketty paljon prosessoreita, jotka hakevat ja tallettavat tietoa keskitettyyn muistiin, syntyy väylässä ruuhkaa joka hidastaa laskentaa. Yksinkertaistettuna voidaan sanoa, että väylän kaistanleveys W pienenee luvuksi W/N jos väylää on jakamassa N kpl prosessoreita. Mitä suuremmaksi kasvatetaan järjestelmän laskentakapasitettia eli mitä enemmän on laskentaan osallistuvia prosessoreita sitä surkeammaksi putoaa väylän siirtokapasiteetti. On siis löydettävä ratkaisu vähentämään väylässä tapahtuvia muistiviittauksia.
Eräs tapa nopeuttaa muistiviittauksia on rakentaa useampi kuin yksi väylä prosessorien käyttöön. Jaettaessa muisti N:ään yhtä suuren osaan ja vedettäessä N:ltä prosessorilta ristiin väylät saadaan muodostettua NxN kokoinen tietoliikenneverkko. Ideaalitapauksessa jokainen prosessori pääsee samanaikaisesti tekemään muistiviittauksia vapaata väylää pitkin. Monen väylän ratkaisuissa ongelmana on niiden vaikea ohjaussysteemit, kalliit rakentamiskustannukset ja näin rakennettujen järjestelmien joustamattomuus, esim. uusien prosessorien lisääminen järjestelmään on vaikeata tai mahdotonta. Toinen tapa, mikä tässä projektissa on tarkoitus toteuttaa, on käyttää edelleen vain yhtä väylää mutta jokaisen prosessorin yhteydessä on pala muistia. Prosessori ja muisti muodostavat yksikön jossa on kaksi väylää. Yksikön sisällä on lokaali väylä ja ulkopuolella järjestelmän yhteinen keskus-väylä. Prosessori voi tehdä nyt muistiviittauksia joko lokaalilla väylällä tai keskusväylällä. Jos prosessorin tarvitsema data on samassa yksikössä, käyttää prosessori luonnollisesti yksikön sisäistä väylää datan noutamiseen. Tällöin keskusväylä jää vapaaksi muiden prosessorien muistiviittauksiin. Jos prosessorin tarvitsema data on jossain muussa prosessoriyksikössä haetaan tarvittava tieto keskusväylän välityksellä. Hyvällä datan jakamisella ja prosessoreille annettujen tehtävien delegoimisella voidaan keskusväylän kuormitusta laskea huomattavasti.
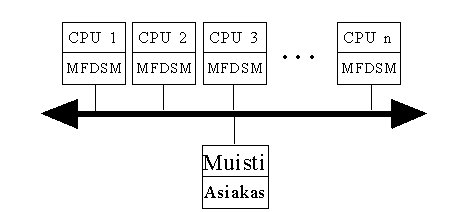
Projektissa tätä hajautetun muistin mallia kutsutaan MFDSM (MultiFunction Distributed Shared Memory) arkkitehtuuriksi. /2/,/3/,/4/ Prosessin yhteydessä on MFDSM muisti, jota pystyy käyttämään sekä lokaalin väylän että keskusväylän välityksellä (kuva 4). MFDSM muisti on edelleen jaettu pienempiin segmentteihin. Nämä segmentit ovat osia jaetusta muistista. Eri MFDSM yksiköillä on mahdollista olla samoja segmenttejä jotka ovat kopioita samasta jaetun muistin osoitteesta. Näiden identtisten muistisegmenttien käyttö vaikeuttaa muistin ylläpitoa koska muistin päivittämisen yhteydessä pitää myös päivittää muissa MFDSM yksiköiden muisteissa olevat segmentit. Toisaalta tämä myös on laskennan kannalta joustavaa koska samaa dataa voidaan käsitellä eri prosessoreilla hakemalla sitä lokaalisen väylän avulla. Näin keskusväylän liikennettä voidaan pienentää.
Kuva 4. MFDSM malli. Asiakas ja n kpl palvelijoita
ovat kytketty samaan keskusväylään.
MFDSM muistin voidaan ajatella olevan välimuistia, joka käyttäytyy kuten normaalit prossessorien välimuistit. Prosessori säilyttää välimuistissaan ne muistipalat mitä sille on annettu. Prosessorin päivittäessä omaa muistisegmenttiään merkitsee se segmentin lukituksi estäen näin muiden prosessorien kirjoitusyritykset. Muut prosessorit joutuvat odottamaan kunnes segmentin lukinnut prosessori poistaa lukituksen.
MFDSM järjestelmässä on mahdollista laittaa jokainen segmentti osoittamaan peräkkäisiin muistiosoitteeseen joilloin saadaan muodostettua maksimaalisen iso muistiavaruus. Segmenttien on myös mahdollista laittaa osoittamaan muistiavaruutta menemällä osaksi päällekkäin toistensa kanssa. Tästä voi olla ajettavasta algoritmistä riippuen hyötyä.
Projektissa MFDSM malli toteutetaan kokonaan tietokoneohjelmilla. Ohjelman alustana käytetään UNIX työasemia. MFDSM mallin keskysväylänä toimii ethernet-verkko ja lokaalisena väylänä toimii luonnollisesti työasemien oma muistiväylä. Ethernet-verkossa ajetaan TCP/IP-protokollaa. Kaikki ohjelmointi tapahtuu C-kielellä. Kokeilupaikkana on fotogrammetrian ja kaukokartoituksen laboratorion UNIX työasemat ja ethernet-verkko.
TCP/IP-protokollassa voidaan paketteja lähettää käyttämällä joko TCP- tai UDP-kuljetusprotokollaa. TCP-protokollassa muodostetaan yhteyspohjainen päästä-päähän tiedonvälitys. Protokolla takaa että paketit saapuvat virheettöminä ja oikeassa järjestyksessä perille. UDP-protokollassa paketteja lähetetään tietosähköperiaatteella ilman erityistä yhteyden muodostamista. UDP-protokolla takaa ainoastaan että paketti on virheetön jos se saapuu määränpäähänsä. Esim. telnet käyttää TCP-protokollaa ja NFS ja SNMP käyttävät UDP:ta.
IP-verkkoprotokollassa määritellään miten muodostetaan internetissä olevien koneiden verkko-osoitteet. Tavallisten A, B ja C-luokkien osoitteiden lisäksi protokolla määrittelee D-luokan eli multicast ryhmän osoitteet (224.0.0.0-239.255.255.255 välillä olevat osoitteet). Tavallisen verkko-osoitteen lisäksi verkossa olevalle koneelle voidaan antaa jokin multicast-osoite. Tällöin kone vastaanottaa sekä omalle verkko-osoitteelle lähetetyt paketit että multicast-osoittelle lähetyt paketit. Multicast-osoite voidaan asettaa ohjelmallisesti suoraan verkkokortille, joilloin kortti automaattisesti kuuntelee multicast-osoitteeseen tulevia viestejä. Useammalla kuin yhdellä koneella voi olla sama multicast-osoite. Koneet joilla on sama osoite muodostavat multicast-ryhmän. Lähetettäessa viesti multicast-osoitteeseen vastaanotetaan se kaikissa multicast-ryhmään kuuluvissa koneissa sen sijaan että viesti pitäisi lähettää jokaiselle vastaanottajalle erikseen. Multicast-viestit eivät rajoitu pelkästään lähiverkkoon vaan ne menevät reitittimistä läpi jos reititin on näin konfiguroitu. Multicast-viestejä voidaan lähettää vain UDP-protokollalla. /5/
Projektissa keskusväylä toteutetaan ethernet-verkossa TCP/IP-protokollalla. Kaikki hajautettuun laskentaan osallistuvat työasemat kuuluvat multicast-ryhmään. Kaikki viestintä verkossa tapahtuu multicast-paketeilla. Koska multicast-paketit lähetetään UDP-protokollalla ei pakettien perillemenosta ole takuita. Tämän takia jokainen paketti merkitään vastaanotetuksi lähettämällä kuittausviesti. Jotta verkko ei tukkeutuisi työasemien lähettämistä kuittausviesteistä käytetään myös kuittauksissa multicast-viestejä ja RFC 1112 standardissa (Host Extensions for IP Multicasting) ehdotettua menetelmää. Jokainen paketin vastaanottanut työasema ei lähetä välittämästi kuittausviestiä vaan arpoo satunnaisen pituisen viiveen, jonka ajan päästä kuittausviesti lähetetään. Jos kuitenkin työasema vastaanottaa toisen multicast-ryhmään kuuluvan työaseman kyseiselle paketille lähetyn kuittauksen ennen oman kuittauksen lähettämistä niin työasema tiputtaa oman kuittauspaketin ja merkitsee paketin kuitatuksi. Näin yhdellä kuittausviestillä koko multicast-ryhmä kertoo paketin vastaanotetuksi./6/
Hajautetun laskennan järjestelmä koostuu asiakkaasta ja yhdestä tai useammasta palvelijasta. Asiakas on prosessi, jossa ajetaan itse pääohjelmaa. Palvelin on prosessi, jossa ajetaan pääohjelmassa määrättyjä koodinpätkiä, jotka käyttäjä on merkinnyt ajettavan hajautetusti. Asiakkaita on vain yksi kun taas palvelimia on yleensä useita. Samassa lähiverkossa voidaan ajaa useita asiakas-palvelin ryhmiä samoissa koneissa.
Sekä asiakas että palvelin prosessit käyttävät samoja ohjelmia. Ohjelmat huomaavat itse ovatko ne käynnistetty asiakas tai palvelin tilassa. Järjestelmä koostuu kahdestä erillisestä ohjelmasta. Jokaisessa verkon laskentaryhmään kuuluvassa koneessa pyörii ylipalvelin, joka asiakkaan kutsun saatuaan käynnistää MFDSM-ohjelman eli palvelijan. Ennen palvelijan käynnistämistä ryhmässä olevat ylipalvelijat neuvottelevat keskenään kaikille vapaan multicast-osoitteen jonka ne antavat kyseisen asiakkaan käytettäväksi. Tämän jälkeen jokainen kone käynnistää oman MFDSM-prosessinsa ja jää kuuntelemaan uusien asiakkaiden kutsuja. Luotu asiakas-palvelin ryhmä on nyt valmis datan ja laskemisen hajauttamiseen.
Jokaisessa koneessa pyörii vain yksi kappale ylipalvelijoita. MFDSM-prosesseja voi pyöriä useita. Myös samalle asiakkaalle voidaan samassa koneessa käynnistää useita MFDSM-prosesseja. Ylipalvelijat huolehtivat myös oman koneensa MFDSM-prosessien valvonnasta ja prosessin tappamisesta tilanteen niin vaatiessa. Jos asiakasprosessi jostain syystä kuolee niin kaikki kyseisen asiakkaan palvelinprosessit myös lopetetaan.
MFDSM-ohjelma voidaan jakaa kolmeen osaan. Tietoliikenneosa huolehtii nimensä mukaisesti kaikesta tiedonvälityksestä mitä ohjelma tarvitsee. Toinen osa, prosessin hallintaosa, pitää huolen mitä muuttujia ja dataa pitää hakea tai päivittää. Lisäksi se valvoo kolmannen osan eli käyttäjän koodin ajosta.
Tietoliikenneosa lähettää ja vastaanottaa paketteja ylipalvelijalta saadulta multicast-osoiteella. Se myös ylläpitää lähetettyjen ja vastaanotettujen pakettien puskuria mahdollisten uusintalähetyksien tai kadonneiden pakettien varalta. Tietoliikenneosa pitää myös kirjaa mitkä paketeista on kuitattu ja huolehtii saapuvien pakettien viivytetystä kuittauksesta.
Asiakaskoodia ajetaan koneessa valvotusti. Jos koodi ajettaessa generoi virheilmoituksen, kaappaa prosessin hallintaosa keskeytyksen itselleen ja päättää mitä sille tehdään. Esim. muistinosoituksessa asiakaskoodi voi viitata muistipaikkaan, jota kyseisessä koneessa ei ole lokaalisesti. Tällöin prosessin hallintaosa selvittää mitä muistipaikkaa yritettiin viitata ja käy hakemassa kyseisen palan dataa asiakkaalta. Tämän jälkeen asiakasohjelma saa jatkaa ajoaan. Prosessin hallintaosa huolehtii myös datan päivittämisestä ja lukitsemisesta. Jos jotain muistipaikkaa juuri sillä hetkellä päivitetään kyseisessä koneessa ei MFDSM-prosessi anna kyseistä muistipaikkaa muitten käyttöön ennenkuin on itse lopettanut päivittämisen.
Jaettu muistin käyttö on ohjelmoijalle helpompaa kuin hajautetun muistin viestinvälitysjärjestelmää käyttävät järjestelmät. Jaetun muistin arkkitehtuurissa ohjelmoijan ei itse tarvitse huolehtia muuttujien ja datan lähettämisestä ja vastaanottamisesta. Ohjelmoija tekee vain muistiviittauksia ja käyttöjärjestelmä, tässä tapauksessa MFDSM ohjelma, huolehtii tiedon hakemisesta. Kaikki tiedon hajautukseen liittyvät yksityiskohdat on piiloitettu ohjelmoijalta, eikä hänen tarvitse niistä välittää.
Seuraavassa esimerkissä verrataan PVM viestinvälitysjärjestelmällä tehtyä C-koodia projektissa suunniteltuun MFDSM järjestelmän C-koodiin. PVM (Parallel Virtual Machine) on ohjelmistopaketti, jolla laskentatehtäviä voidaan hajauttaa useille kymmenille prosesseille viestinvälitysohjelmointia hyväksikäyttäen. PVM on kehitetty Oak Ridge National Laboratoryn, University of Tenneseen, Emory Universityn ja Carnegie Mellonin tutkijoitten yhteystyönä. Ensimmäinen julkinen versio ohjelmasta tuli Internettiin vuonna 1991. Ohjelma on erittäin suosittu ja sille on tehty oma Usenet-keskustelufoorumi (comp.parallel.pvm), missä käyttäjät esittelevät omia ideoitaan. Käyttäjien palautteiden ansiosta PVM on nykyään lähes virheetön ja kohtalaisen käyttökelpoinen./7/
Esimerkkiohjelmana tehdään ohjelma, joka luo asiakkaalle palvelijat jotka palauttavat prosessinumeronsa asiakkaalle.
#include <stdio.h>
#include "pvm3.h"
#define NPROC 4 /* Prosessien kokonaismäärä*/
int main()
{
int taskid[NPROC], ME, msglabel, i;
int mytid = pvm_mytid();
int parent = pvm_parent();
msglabel = 1000;
if (parent < O) { /* Asiakasosa */
pvm_spawn("server",NULL, PvmTaskDefault,"*",
NPROC-1, &taskid[1]);
taskid[O] = mytid;
pvm_initsend(PvmDataDefault);
pvm_pkint(taskid,NPROC,1);
pvm_mcast(ttaskid[1],NPROC-1,msglabel);
ME = O; msglabel = 1500;
for (i=1; i<NPROC; i++) {
int who;
pvm_recv(-1,msglabel);
pvm_upkint(&who,1,1);
printf("%d: hello world from process %d!\n",i,who);
}
}
else { /* Palvelinosa */
psm_recv(parent,msglabel);
pvm_upkint(taskid,NPROC,1);
for (i=O; i<NPROC; i++) {
if (taskid[i] == mytid) ME = i;
}
msglabel = 1500;
pvm_initsend(PvmDataDefault);
pvm_pkint(&ME,1,1);
pvm_send(parent,msglabel);
}
pvm_exit();
return O;
}
Ohjelman alussa pvm_mytid käynnistää PVM
virtuaalikoneen. pvm_parent:in palauttama arvo kertoo prosessille
onko tämä asiakas vai palvelin. Asiakas käynnistää
pvm_spawn käskyllä palvelijat. Jotta palvelimet
voisivat kommunikoida keskenään on niille kerrottava
toistensa prosessitunnisteet. Asiakasosassa pvm_initsend,
pvm_pkint ja pvm_mcast alustavat, täyttävät
ja lopulta lähettävät viestit palvelijoille. Palvelijat
taas vastaanottavat prosessitunnisteet pvm_rec ja pvm_upkint
käskyillä. Tämän jälkeen palvelijat lähettävät
oman prosessitunnisteensa asiakkaalle. Asiakas käyttää
samoja pvm_rec ja pvm_upkint vastaanottamaan viestit
ja tulostaa ne lopulta ruudulle. Sekä asiakas ja palvelijat
lopettavat tämän jälkeen PVM virtuaalikoneen (pvm_exit)
ja ohjelman suorittaminen loppuu.
#include <stdio.h>
#include <mfdsm.h>
void *return_pid();
struct {
int *pointer;
} function_arguments;
main(int argc, char *argv[])
{
struct function_arguments Args;
int n, i, *p, taskid[10];
n = MFDSM_Init(argc, argv);
printf("We have %d servers available\n", n)
MFDSM_Malloc(1*sizeof(int));
for(i = 0; i < n; i++){
p = (int *)MFDSM_Mapp(i, taskid[i], 1);
Args.pointer = p;
MFDSM_Run(return_pid, &Args);
}
for(i=0; i < n; i++)
printf("%d: hello world from process %d!\n",i,
taskid[i]);
exit(0);
}
/* Palvelimissa ajettava aliohjelma */
void return_pid(struct function_arguments *Args )
{
*(Args->pointer)=getpid();
return;
}
Ohjelman alussa MFDSM_Init käskyllä alustetaan
MFDSM järjestelmä ja käynnistetään verkossa
kaikki palvelijat. MFDSM_Init palauttaa verkossa löytyneitten
palvelijoiden lukumäärän. MFDSM_Malloc allokoi
yhden kokonaisluvun kokoisen palan jokaisessa palvelijassa. MFDSM_Map
muodostaa asiakasprosessissa linkin jokaiselle palvelijalle allokoidun
muistipaikan ja taskid:n alkioiden välillä. Tämän
alustuksen jälkeen ajetaan palvelijoissa return_pid
niminen aliohjelma MFDSM_Run käskyllä. Palvelijoissa
return_pid aliohjelma tallettaa saamaansa argumenttiin
oman prosessitunnisteensa ja lopettaa. Asiakasohjelma on tällävälin
mennyt ohjelmassa eteenpäin ja odottaa seuraavan for-silmukan
kohdalla että palvelijat vapauttavat lukitsemansa taskid:n
alkiot. Kun alkio on vapautettu tulostetaan hello world!
ruudulle.
Ohjelmien esimerkeistä näkyy selvästi mikä ero on viestinvälitysjärjestelmien ja jaetun muistin järjestelmien koodeissa. PVM ohjelmassa käytetään yhteensä neljäätoista järjestelmäkutsua kun MFDSM ohjelmassa selvitään neljällä. Ohjelmien muuttuessa monimutkaisemmiksi kuin esimerkkiohjelmat eron huomaa vielä selvemmin. Jaetun muistin järjestelmää käyttäviä ohjelmia on helpompi ohjelmoida koska järjestelmä piiloittaa kaiken kommunikaation ohjelmoijalta.
Hajautettu laskenta nopeuttaa ohjelmien ajamista ja lisää vikasietoisuutta. Se sopii erittäin hyvin etenkin digitaalisen kuvankäsittelyn alueelle, sillä ala on luonnostaan rinnakkaiseen laskentaan sopivaa. Hajautetulla laskenta voidaan erilaisen arkkitehtuurin mukaan jakaa joko viestinvälitysjärjestelmiin tai jaetun muistin järjestelmiin. Viestinvälitysjärjestelmässä prosessorit kommunikoivat keskenään lähettelemällä viestejä toisilleen tietoliikenneverkon välityksellä. Jaetun muistin järjestelmässä prosessorit välittävät muuttujia ja dataa käyttämällä yhteistä muistiavaruutta. Kummassakin järjestelmässä laskentanopeuden jarruna on tietoliikenteen nopeus.
Fotogrammetrian ja kaukokartoituksen laboratoriossa tehtävässä projektissa suunnitellaan järjestelmää, jossa jaetun muistin mallia toteutetaan usealla UNIX työasemalla ethernet-verkossa. Tätä MFDSM (MultiFunction Distributed Shared Memory) mallilla pyritään saamaan aikaiseksi järjestelmä, joka sopii erityisen hyvin digitaalisessa fotogrammetriassa tarvittaviin algoritmeihin, jotka liittyvat tietokonenäköön ja digitaaliseen kuvankäsittelyyn.
/1/ K. Hwang & F.A. Briggs, Computer Architecture and Parallel Processing, McGraw-Hill, 1985
/2/ Min Gong, Introduction to Multiprocessor Architecture for Image Processing, The photogrammetric journal of Finland, Vol.12, numero 1, 1990
/3/ Ming Gong, Attempt to sole memory access conflict problem in multiprocessor environment MultiFunction Distributed Shared Memory Architecture, Distributed Operating Systems and Mach, TKK-Tietojenkäsittelytekniikan laitos, Otaniemi, 1993
/4/ Min Gong, haastattelu 18.3.1996
/5/ Kari Saarelainen, Lähiverkkojen tekniikka, Yritysmikrot, 1993
/6/ RFC 1112, Host Extensions for IP Multicasting
/7/ Sami Saarinen, Rinnakkaislaskennan perusteet PVM-ympäristössä, Yliopistopaino, 1995
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}