S-38.116 TELETIETOTEKNIIKKA
Seminaariaihe:
Puheenkoodaus tietoliikenteessä
Johan Hæggström, 40457h
Johan.Haeggstrom@ntc.nokia.com
ACELP Algebraic CELP, algebraallinen CELP
ADPCM Adaptive Differential PCM, adaptiivinen differentiaalinen PCM
APC Adaptive Predictive Coder, adaptiivinen prediktiivinen kooderi
APCM Adaptive PCM, adaptiivinen PCM
ARMA Auto-Regressive Moving Average, napa-nolla suodin
CCITT Comité Consultatif International Télégraphique et Téléphonique, vuonna 1993 ITU korvasi CCITT:n
CELP Code-Excited Linear Prediction, koodiherätteinen lineaari prediktio
CS-ACELP Conjugate Structure ACELP, ITU-T G. 729 koodekin algoritmi
DAM Diagnostic Acceptability Measure, puhelaadun mitta
DCT Discrete Cosine Transform, diskreetti kosinimuunnos
DM Delta Modulation, delta modulaatio
DPCM Differential PCM, differentiaalinen PCM
DRT Diagnostic Rhyme Test, puhelaadun mitta
DSP Digital Signal Processing, digitaalinen signaalinkäsittely
DTX Discontinuous Transmission, epäjatkuva lähetys
EFR Enhanced Full Rate, parannettu täyden nopeuden kanava
FDHS Frequency Domain Harmonic Scaling, taajuusalueen harmooninen skaalaus
FR Full Rate, täyden nopeuden kanava
GSM Global System for Mobile communication, yleis-eurooppalainen digitaalinen matkapuhelin standardi
HR Half Rate, puolen nopeuden kanava
IMBE Improved MBE, parannettu MBE
ISDN Integrated Services Digital Network, yleisen puhelinverkon digitaalinen standardi
ITU-T International Telecommunications Union - Telecommunication, kansainvälinen tietoliikenteen etujärjestö
KLT Karhunen-Löve Transform, Karhunen-Löve muunnos
log-PCM logarithmic PCM, logaritminen PCM
LPC Linear Predictive Coding, lineaari prediktiivi koodaus
LSP Line-Spectral Pairs, viivaspektri pari
LTP Long-Term Prediction, pitkän aikavälin ennustus
MBE Multi-Band Excitation
MOS Mean Opinion Score, subjektiivinen asteikko
MPEG Moving Picture Expert Group, digitaalisen videon sekä audion standardointi työryhmä
NFC Noise Feedback Coding, kohinan takaisinkytkentä koodaus
PCM Pulse-Code Modulation, pulssikoodi modulaatio
PCM-AQ PCM Adaptive Quantizer, PCM adaptiivisella kvantisoijalla
PSI-CELP Pitch Synchronous Innovation CELP, Japanin PDC-järjestelmän puolen nopeuden puhekoodekki
PSTN Public Switched Telephone Network, yleinen puhelinverkko
SNR Signal-to-Noise Ratio, signaali kohina suhde
STC Sinusoidal Transform Coding, sinimuunos koodaus
STFT Short-Time Fourier Transform, lyhyen aikaikkunan Fourier muunos
TASI Time Assignment Speech Interpolation, pakettiverkoissa kapasiteettia säästävä algoritmi
TDHS Time Domain Harmonic Scaling, aika-alueen harmooninen skaalaus
TFI Time-Frequency Interpolation, aika-taajuus interpolaatio
US-CDMA United States - Code Division Multiple Access, USA:ssa kehitteillä oleva digitaalinen matkapuhelinjärjestelmä
V/UV Voiced / UnVoiced, soinnillinen / sonniton
VAD Voice Activity Detection, puheaktiviteetin ilmaisin
VFR Variable Frame Rate, tapa koodata vaihuvalla nopeudella
VQ Vector Quantization, vektorikvantisointi
VSELP Vector-Sum Excited Linear Prediction, GSM:n HR-kanavan puhekoodekki
VXC Vector Excitation Coding, CELP-algoritmin variantti
WI Waveform Interpolation, granulaari koodaukseen kuuluva algoritmi
WLP Warped Linear Prediction, vääristetyllä taajuusasteikolla laskettu LPC
a-laki muunnos kaava jonka mukaan euroopassa lasketaan logaritminen PCM
aaltomuotokoodaus puhekoodaus, jossa ei oteta kantaa puhetuottoon
all-pole suodin, jossa on vain napoja (=IIR)
auditoorinen kuulojärjestelmän mukainen
formantti puhespektrissä esiintyviä korostumia
u-laki muunnos kaava jonka mukaan pohjoisamerikassa ja Japanissa lasketaan logaritminen PCM
vektorikvantosointi kvantisointi jossa käsitellään joukko arovoja kerrallaan
vokooderi muodostuu sanoista: "voice coder / decoder", puheenkoodaaja
1. Johdanto
Puheenkoodausta alettiin tutkia 1950-luvulla, alunperin sotateollisuuden sovelluksia varten. Kehiteltiin vokoodereita, jotta ymmärrettävää puhetta saataisiin siirrettyä huonojen analogisten siirtojohtojen läpi. Puhesignaalin kaistanleveys saatiin kaven-nettua sekä siirtovirheiden suojausta voitiin toteuttaa vokoodaus tekniikoilla. Sota-teollisuuden kannalta oli myös tärkeätä, että vokoodaus oli tapa salata puhetta. Tunnetuin, USA:n armeijan kehittämä vokooderi, on "US Federal Standard 1015" (tunnetaan myös nimeltä LPC-10) vuodelta 1975. Samoihin aikoihin CCITT oli kehittänyt digitaaliseen puheensiirtoon tarkoitetun standardin (G. 711). CCITT ja myöhemmin ITU-T on jatkanut puhekoodekkien standardointia. [1] (Katso taulukko 1.)
Taulukko 1. International Telecommunication Union:n puheenkoodaus standardeja. [1]
Puheenkoodauksen uusi sovellusalue on muodostunut dominoivaksi viimeisen vuosi-kymmenen aikana. Digitaalisten matkapuhelin- ja satelliittiverkkojen puheenkoodaus standardeja syntyy jatkuvasti.
Puheenkoodaus tekniikat voidaan jaotella eri tavoin. Perinteisesti, vookoodaus ja aaltomuotokoodaus muodostaa kaksi pääryhmää. Valitettavasti tämä luokittelu ei voida soveltaa nykypäivän "state-of-the-art" koodekkeihin. Tekstin loppussa on ehdo-tettu kattavampi luokittelutapa.
Tosiaika toteutuksissa laskennallinen kuormittavuus voi muodostua ongelmaksi. Koodekin on pystyttävä sekä koodaamaan että dekoodamaan mahdollisimman viiveettömästi. Vaatimukset muistikoon suhteen voi myös olla toteutuksessa ratkaiseva tekijä. Puheenkoodaus on laskennallisesti vaativaa, jonka toteuttamiseen soveltuu digitaaliset signaalinkäsittely piirit (DSP piirit).
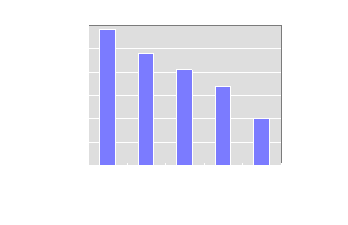
Korkealuokkaisen audiosignaalin vaatima siirtonopeus on melkein 1 Mbit/s. Puheen tunnistukseen ja synteesiin perustuva puhekoodekki siirtää vain noin 100 bit/s. Käytössä olevien puhekoodekkien siirtonopeudet ovat muutaman sadan bit/s:n ja 64 kbit/s:n välillä. (Katso kuva 1.) Puheenkoodaus on pääosin häviöllistä, joten on tehtävä kompromissi puhelaadun ja siirtonopeuden suhteen.
Koodatun puheen laadun mittaaminen on vaikeata, koska objektiivisten mittalaitteiden antama tulos, esim. SNR (signaali kohina suhde), ei ole riittävä. Yleisesti käytetään subjektiivista mitta-asteikkoa, MOS-arvot 1-5, jossa lankaverkon puhelaatu vastaa arvoa 4 tai yli. (Myös kaikki ITU:n puhekoodekit ylittävät MOS-arvon 4.) Matka-puhelinverkkoissa vaaditaan puheen laadulle vähintään MOS-arvoa 3,5. Puhe kutsutaan yleenä synteettiseksi mikäli MOS-arvo alittaa 3,5. Subjektiivisistä testeistä saadut tulokset voidaan verrata vain testattujen koodekkien kesken. Jotta testi olisi yleispätevä on MOS-arvot skaalattava jonkun referenssikoodekin mukaan. Synteettiseltä kuulostavien koodekkien testaamiseen voidaan käyttää myös objektiivisia mittausmenetelmiä, joista mainittakoon "Diagnostic Rhyme Test" (DRT) ja "Diagnostic Acceptability Measure" (DAM). [1], [2]
Kuva 1. Koodatun puheen ja korkealuokkaisen audion siirtoon tarvittava bitti-nopeus. Vasemmalta oikealle: 1) yksikanavainen cd-ääni, 705.6 kbit/s 2) ITU:n standardi G. 711, 64 kbit/s 3) GSM:n täyden nopeuden puhekanava, 13 kbit/s 4) US Federal Standard 1015 vokoodaus, 2.4 kbit/s 5) "reaaliaikainen" tekstin siirto, ~0.1 kbit/s.
2. Puhesignaalin bittinopeuden alentamisen
perusperiaatteet
Poistamalla toistuvia komponentteja puheesta voidaan korkealuokkaista puhetta
koodata noin 10 kbit/s:n nopuedella. Verraten yksinkertaisin menetelmin voidaan
reilusti vähentää biittimäärää
heikentämättä puheen laatua. Seuraavassa
käsitellään puheelle ominaisia piirteitä, joita voidaan
hyödyntää puheenkoodauksessa.
2.1 Puheen spektri
Puheen pitkän aikavälin spektrissä on hyvin vähän
energiaa 4 kHz:n yläpuolella. [3] (Katso kuva 2.) Tietyt
äänteet kuten frikatiivit (esim. /s/ ja /f/) sekä plosiivit
(esim. /k/, /p/ ja /t/) muodostavat laajakaistaisen kohinan. Korkeat taajuudet
eivät ole kuitenkaan puheen ymmärrettävyyden kannalta
tärkeitä. Nyqvistin teoreeman mukaan 8000 näytettä/s on
riittävä nutteenottotaajuus 4 kHz:n kaistan
näytteistämiseen. Jotta puhe säilyisi korkealuokkaisena
vaaditaan 12 bittiä/näyte, jolloin bittinopeudeksi muodostuu 96
kbit/s. [4] PSTN:ssä (Public Switched Telephone Network) tilanne ei
valitettavasti aina ole yllä kuvatun kaltainen. Vain taajuudet 300 - 3400
Hz läpäisevät puhelinverkon ja huonojen analogisten
siirtojohtojen takia, SNR on usein reilusti alle vaaditun (30 dB).
Kuva 2. Puheen pitkän aikavälin spektri. [3]
2.2 Epätasavälinen kvantisointi
Logaritminen PCM (Pulse-Code Modulation) bittinopuedella 64 kbit/s (esim. ITU:n
standardi G. 711) on paljon käytetty puheen digitaalisessa siirroossa.
Log-PCM tekniikalla koodattua puhetta käytetään
referenssinä, johon muita koodaus-mentelmiä verrataan. Tavallisesta
näytteistämisestä log-PCM eroaa vain kvantisoinnin kohdalta,
jossa se käyttää epätasavälistä kvantisointia. 8
bitin logaritminen kvantisoija vastaa laadultaan 12 bitin lineaari
kvantisoijaa. Tämä selviää tutkimalla puheen pitkän
aikavälin amplitudijakaumaa. [3] (Katso kuva 3.)
Näytteistetyssä puheessa on enem-män pieniä arvoja kuin
suuria. Logaritminen kvantisoija, joko a-lain (eurooppa) tai u-lain
(pohjoisamerikka ja Japani) mukainen, käyttää tiheää
askelkokoa pienille arvoille ja tietyn rajan yläpuolella askelkoko kasvaa
logaritmisesti.[1
]
Kuva 3. Puheen pitkän aikavälin amplitudijakauma. (Huomaa pystyakselin logarit-minen asteikko.) [3]
Puheenkoodaus on optimoitu puheen siirtämiseen. Aaltomuotokoodaus soveltuu kuitenkin melko hyvin myös audiosignaalien siirtämiseen. Aaltomuotokoodekit hyö-dyntävät vain puhesignaalin tiettyjä ominaisuuksia, eikä mallinna puheentuotto mekanismia. Seuraavassa on esitelty aaltomuotokoodauksen perusmenetelmät. ]
Adaptiivista kvantisoijaa käyttävä PCM (APCM tai PCM-AQ), muuttaa kvantisoijan askelkokoa näytteiden lyhyen aikavälin keskiarvon mukaan. Kvantisoija voi adap-toitua joko taaksepäin tai eteenpäin.
Tehokas tapa poistaa puhesignaalin lyhyen aikavälin korrellointia on kvantisoida kahden näytteen erotus. Kaikessa ennustamiseen perustuvassa puheenkoodauksessa on eduksi mikäli erotussignaalin amplitudia saadaan pienennettyä, koska tämä puolestaan kasvattaa signaalin entropiaa. Differentiaalinen PCM (DPCM) perustuu tähän ideaan ja se käyttää joko ensimmäisen tai toisen asteen lineaari ennustajaa. (Myöhemmin on kuvattu lineaarisen ennustajan toimintaa.)
AD-muuntimista tuttu delta modulaatio (DM), käytetään myös puheenkoodaukseen. Signaalin muutos kuvataan yhdellä bitillä (joko lisätään tai vähennetään ennustettuun arvoon), joten DM on hyvin samankaltainen kun DPCM. Jotta yhden bitin tarkkuus olisi riittävä, on käytettävä huomattavasti korkeampaa näytteenotto taajuutta. Puhe-signaalin synkronoinnissa voi olla hyödyksi kasitellä vain yhtä bittiä kerrallaan, koska silloin ei tarvitse lukittua tiettyyn bittikuvioon.
DPCM:ä voidaan edelleen parantaa kohinan takaisinkytkennällä (NFC) tai adap-tiivisella jälkisuodatuksella. Nämä menetelmät hyödyntävät kuulojärjestelmän rajoi-tuksia, joita käsitellään kappaleessa 3.4.
Yhdistämällä DPCM ja APCM saadaan adaptiivinen differentiaalinen PCM (ADPCM), jota käytetään esim. ITU:n G. 721 puhekoodekissa. Tämä koodekki tuottaa saman laatuista puhetta kuin G. 711 (64 kbit/s log-PCM), mutta bitti-nopeudella 32 kbit/s.
Pitkän aikavälin ennustajaa voidaan käyttää
puhesignaalin perustaajuus komponentin poistamiseen. (Tästä on vain
vähän hyötyä soinnittomien äänten kohdalta.)
Adaptiiviset prediktiiviset kooderit (APC) käyttävät joko
ensimmäisen tai kolmannen asteen ennustajaa, jonka toimintaa on kuvattu
kappaleessa 3.2.
Taajuusalueen aaltomuotokoodaus
Puhespektrin kaikki alueet eivät ole tärkeitä, korkealaatuisen
puheen toistoon. Puhesignaalin bittimäärää voidaan
vähentää niin, että vähemmän tärkeät
taajuuskaistat koodataan pienemmällä
bittimäärällä. Kaistanpäästösuotimella
jaetaan spektri 4-8:an ei-päällekkäiseen kaistaan ja suotimen
huolellinen suunnittelu on erityisen tärkeätä. Kaistojen
keskitaajuudet pyritään sijoittamaan puheen formanttien kohdille.
Ali-kaistojen leveydeksi muodostuu noin 500 Hz, joten näytteenotto
taajuutta voidaan alentaa 1000 Hz:in. Bittinopeutta saadaan yhä alennettua
APCM koodaamalla alikaistat. Kvantisointikohina pysyy kaistojen
sisällä APCM-alikaista koodauksessa, joten vierekkäiset kaistat
eivät häiritse toisiaan. Parhaimmat alikaistakoodekit pysty-vät
tuottamaan ymmärrettävää puhetta jopa nopeudella 4,8
kbit/s. Nämä käyttävät kehittynyttä tekniikka
formanttien seurantaan, jolloin kaksi korkeinta alikaistaa lukittuvat toiseen
ja kolmanteen formanttiin.
Puheen spektri muuttuu verraten hitaasti, johtuen puheentuottoelinten
liikeratojen rajoituksista. Ääniväylä (suu+nielu) ei
yksinkertaisesti pysty kuinka nopeasti tahansa muuttamaan muotoaan.
Muunnoskoodekki lähettää hitaasti muuttuvan spektrin.
Optimaalinen koodekki käyttää Karhunen-Löve muunnosta
(KLT), mutta tosiaika toteutuksissa tämä on laskennallisesti liian
vaativa. Lähes yhtä tehokas, mutta huomattavasti helpompi laskea, on
diskreetti kosini muunnos (DCT). Puheen spektri on vakaa noin 15 ms:n ajan,
joka vastaa 120 näytteen maksimaalista muunnosikkunaa. Kuten
alikaistakoodekkien kohdalla, muunnoskoodekit keskittävät bitit vain
tärkeille taajuusalueille. Usein yhdistetään muunnoskoodaus
johonkin toiseen koodaus-menetelmään, esim. logaritminen kvantisointi
tai alikaistakoodaus. Harmooninen koodaus muistuttaa muunnoskoodausta, mutta on
tässä käsitelty vokoodaus teknii-koiden yhteydessä,
kappaleessa 4.1.
3. Puheentuottomalliin perustuva puheenkoodaus
Tehokkain puheenkoodaus toteutetaan puheentuottomallin avulla. Eniten käytetty malli on esitetty kuvassa 4. Herätesignaali ohjataan ajassa muuttuvaan digitaali-suotimeen, joka vastaa äänihuulten synnyttämän äänen muokkautumista ääniväylässä. Herätesignaali vaihtelee kohinasta (soinnittomille äänteille) impulssijonoon (soinnil-lisille äänteille). Mallia voidaan parantaa käyttämällä parempaa herätesignaalia, esim. ääniväylän käänteissuotimen jäännössignaalia.
Kuva 4. Yksinkertainen puheentuottomalli. [3]
3.1 Lineaari prediktio koodaus
Ääniväylän mallintamiseen soveltuu erityisen hyvin lineaari
prediktio koodaus (LPC). Puhenäyte voidaan esittää edellisten
näytteiden linneaarisena kombinaationa, jolloin puhesignaalista saadaan
poistettua toistuvia komponentteja. Lineaari ennustaja on muotoa
Click here for Picture (3.1)
missä p on ennustajan asteluku, eli monenko näytteen yli lasketaan korrellaatio, ja Click here for Picture :t ovat ennustuskertoimet. Asteluvulle p käytetään yleensä lukua 8-12. LPC synteesisuotimen siirtofunktio on muotoa
Click here for Picture (3.2)
Ennustuskertoimien, Click here for Picture , lisäksi on laskettava vahvistuskerroin, G. Yllä oleva autoregressiivinen (AR) malli pystyy tyydyttävästi estimoimaan suurimman osan äänteistä. LPC parametrit lasketaan lyhyille ajanjaksoille, 10-20 ms, jona aikana ääniväylä pysyy lähes paikallaan.
LPC-parametrien laskemiseen on käytössä useita menetelmiä.
Kolme yleisintä ovat autokorrellaatio-, kovarianssi- sekä
ristikkomenetelmä. LPC:tä voidaan, puheen-koodauksen lisäksi,
käyttää esim. puheen perustaajuuden, formanttien sekä
spektrin määrittämiseen.
3.2 Pitän aikavälin ennustukseen perustuva
puheenkoodaus
LPC suodatetun puheen jäännössignaali sisältää
jaksollisen komponentin. Tämä esiintyy soinnillisissa
äänteissä ja jaksollisuus voidaan poistaa pitkän
aikavälin ennustuksella (LTP). Ensimmäisen asteen ennustaja on
yleensä riittävä.
Click here for Picture (3.3)
missä [[beta]] on ennustajan vahvistuskerroin ja M on jaksonpituus. LTP synteesisuotimen siirtofunktio on muotoa
Click here for Picture (3.4)
3.3 Puheparametrien sekä jäännössignaalin
vektorikvantisointi
LPC ja LTP suodatettua puhetta voi vielä ymmärtää, eli se
ei ole läheskään satun-naista. [1] Redundanssia, signaalissa
esiintyvää toistuvuutta, voidaan edelleen poistaa
vektorikvantisoimalla (VQ) puheparametreja sekä
jäännössignaalia. Tämä tarkoittaa, että useampi
numeroarvo käsitellään kerrallaan, siis arvot kootaan
vektoreina. Jos vektoreiden esiintymis todennäköisyydet vaihtelevat,
vektoreiden arvot korreloivat. Näin voidaan pienentää kokonais
bittimäärää, menettämättä informaatiota. On
muodostettava koodikirja, joka sisältää sopivan otoksen
vektoriavaruudesta. Koodi-kirjan suunnittelu sekä algoritmi oikean
vektorin löytämiseen ovat VQ:n keskei-simmät asiat.
3.4 Kuulojärjestelmän rajoitusten hyödyntäminen
puheenkoodauksessa
Esi- ja jälkisuodatus on vakiintunut nykypäivän puhekoodekeissa.
Esisuodatus, johon riittää ensimmäisen asteen
ylipäästösuodin, korostaa puheen tärkeimmät
taajuusalueet. Jälkisuodatus on huomattavasti monimutkaisempi.
Käytetään adaptiivista napa-nolla (ARMA) suodinta, jota ohjaa
lyhyen aikavälin ennustaja. Jälkisuodatuksen tarkoi-tuksena on
kasvattaa formanttihuippujen ja -laaksojen eroa. Perustaajuutta korostavaa
jälkisuodinta käytetään myös usein. [1], [7]
NFC:ssä, jota mainittiin kappaleessa 2.4, ylipäästösuodatataan kvantisointikohina, joka parantaa subjektiivista puhelaatua. Jotkut koodekit (kuten CELP-tyyppiset) käyttävät "painotussuodinta", joka mallintaa kuulojärjestelmää. "Varpattu" lineaari prediktio (WLP) käytää kuulon mukaista vääristettyä taajuusasteikkoa. WLP:llä voidaan näin alentaa ennustajan astelukua, tosin laskentamäärä astelukua kohden kasvaa. [8] Laajempien auditooristen mallien käyttöä, kuten MPEG audiokoodekeissa, on toistaiseksi kokeiltu vain vähän, koska tämä kuormittaa huomattavasti laskentaa. [9]
4. Erittäin alhaisten bittinopeuksien puheenkoodaus
algoritmit
GSM:n puolen nopeuden kanavan (HR) standardointi saatiin päätökseen vuoden 1995 aikana. HR-kanavassa käytetään eri puheenkoodaus menetelmää kuin, nykyisin käy-tössä olevassa, täyden nopeuden kanavassa (FR). Puheenkoodaus algoritmi on VSELP (Vector-Sum Excited Linear Prediction), joka koodaa nopeudella 5,6 kbit/s. [10] HR-kanavan puhelaaduksi on saatu sama kuin FR-kanavan (13 kbit/s), mm. huomioimalla seuraavat asiat:
· Vaiheinformaatio voidaan jäättää huomioimatta, sillä korva on epäherkkä vaihevääristymille.
· Perustaajuuden estimointia voidaan parantaa käyttämällä korkeamman asteen ennustajaa sekä murtoviivelaskentaa.
· Bitit voidaan jakaa joustavasti puheparametrien sekä herätteen kesken.
Alikaistakoodauksessa (esitetty kappaleessa 2.4) jaetaan puhespektri 4-8 kaistaan. Kasvattamalla kaistojen määrää vähintään 15, jokainen kaista on kyllin kapea sisältääkseen vain yhden harmoonisen. Puhe voidaan näin koodata harmoonisten summana (amplitudi sekä vaihe). Tämä tekniikka on nimeltä harmooninen koodaus. Harmoonisten löytäminen voi olla vaikeata, joten helpompi tapa koodata alikaistat on kompressoida (3:1) ne koodausvaiheessa ja vastaavasti samassa suhteessa ekspan-doida ne dekooderissa. Tätä kutsutaan taajuusalueen harmooniseksi skaalaukseksi (FDHS). Vastaavaa kompandointia on kokelitu myös aika-alueessa, jota kutsutaan aika-alueen harmooniseksi skaalaukseksi (TDHS). Kompressointi suoritettaan TDHS:ssä yli yhden perustaajuus jakson. Erittäin hyviä koodaustuloksia on saavutettu yhdistämällä harmooninen koodaus johonkin muuhun koodaus tekniikkaan. Vaihe-vokoodaus eroaa harmoonisesta koodauksesta vain siinä, että harmoonisten vaihe derivoidaan ennen lähetystä.
Kanavavokoodausta toteutettiin analogi tekniikalla jo yli 40 vuotta sitten. Siinä käytetään vastaavaa kaistanjakoa kuin harmoonisessa koodauksessa, mutta jokainen kaista tasasuunnataan ja alipäästösuodatetaan, jakotaajuudella 10-20 Hz, jolloin saadaan kaistan amplitudi. Kaistojen tasot sekä soinnillisuus, soinnillinen/soinniton (V/UV), lähetetään vastaanottopäähän.
Formanttivokooderi estimoi puheen formanttien tasot ja kaistanleveydet, mikä sinänsä on osoittautunut erittäin vaikeaksi. Artikulatoorinen vokooderi laskee parametrisen mallin ääniväylästä sekä glottisherätteestä, toisin sanoen fysikaalisen mallin puheen-tuotosta.
Puheen kepstristä saadaan selville puheen perustaajuuden sekä estimaatin ääni-väylälle. Kepstri lasketaan siten, että puheen spektrin logaritmi muunnetaan takaisin aika-alueeseen. Soinnilliset äänteet synnyttävät kepstriin piikin, jonka etäisyys origosta määrää perustaajuuden. Loput kepstristä vastaa ääniväylän impulssivastetta. Kepstri-analyysia käyttävä vokooderi kutsutaan homomorfiseksi vokooderiksi.
Puhe voidaan jakaa segmentteihin, kuten sanoihin, foneemeihin tai vielä
pienempiin osiin. Lähettämällä vain indeksin jokaista
segmenttiä kohden, saadaan bittinopeutta reilusti laskettua.
Puheparametreja, esim. LPC-kertoimia, voidaan myös segmentoida (mikä
vastaa VQ:ia). Erikoistapaus segmenttivokooderista on puheen tunnistukseen ja
synteesiin perustuva koodekki, jossa jopa 100 bit/s on käytetty. [11]
Mozer vokooderi on sääntöpohjainen koodekki, joka
käsittelee puheen perustaajuuden mittaisia komponentteja.
4.2 LPC laskentaan perustuvat vokooderit
LPC-kertoimia voidaan esittää monessa eri muodossa. GSM:n FR kanavan
koode-kissa kertoimet muunnetaan logaritmisiksi pinta-ala suhteiksi (log-area
ratio). Viiva spektri pari (LSP) esitys on ehkä paras LPC-kertoimien
esitysmuoto. Kuten jo mainittiin kappaleessa 3.3, VQ:ia voidaan
käyttää parametri joukon koodaamiseen. VQ
käytetään usein LPC-kertoimien (jonkin esitysmuodon)
koodaamiseen, jopa niin että kehysten välistä toistoa
pyritään vähentämään. LPC-vokoodereissa on
pystytty alentamaan bittinopeutta 150 bit/s, menettämättä puheen
ymmärrettävyys. [12] Lisää-mällä herätteen
soinnillisuusasteita (V/UV:n lisäksi) voidaan LPC-vokooderin puhe-laatua
parantaa.
Analyysi synteesin kautta menetelmä
Koodiherätteinen lineaari prediktio (CELP) on ollut hallitseva
puheenkoodaus menetelmä viimeisten viiden vuoden aikana. CELP-koodekin
alkuperäinen versio on hyvin tehokas, muutta laskennallisesta raskas.
(Katso kuva 5.) Se käyttää LPC- sekä LTP-laskentaa
yhdistettynä jäännössignaalin VQ:in. Suurin osa kooderin
laskennasta kuluu itse asiassa dekoodaukseen, koska "ideaali" tilanteessa
käydään läpi kaikki VQ-koodikirjan herätevektorit,
jotta löytyisi sopivin.
CELP-algoritmi on vuodelta 1985. [14] Siitä lähtien, CELP-tutkimus on keskittynyt enkooderin laskennan rajoittamiseen. On kokeiltu esim. koodikirjan pienentämistä, herätevektorin hakualueen rajoittamista (puuhaku jne.) sekä useiden pienten koodi-kirjojen käyttöä. Koodikirjoja voidaan optimoida tietyille äänteille, mikäli niitä on useampi käytössä. [1]
ITU on äskettäin saanut päätökseen uuden CELP-tyyppisen koodekin standandoinnin. Koodekki on saanut nimeksi G. 729 ja käyttää tarkemmin ottaen CS-ACELP nimistä algoritmia. Tämä koodekki pystyy bittinopeudella 8 kbit/s tuottamaan (eri olosuh-teissa) lankaverkon laatuista puhetta (MOS yli 4). GSM:n parannettuun täyden nopeuden kanavaan (EFR) on valittu myös ACELP koodekki. [1], [15]
CELP-algoritmin pohjalta on kehitelty useita variantteja, esim. VSELP [10], PSI-CELP [16] ja VXC [17]. CELP:n perusluonteesta johtuen se ei sovellu tilanteisiin, missä on koodattava alle 4 kbit/s nopeudella. On itse asiassa osittautunut todella vaikeaksi kehittää puhekoodekkeja, jotka soveltuisivat tulevaisuuden erittäin alhaisten bittinopeuksien matka-puhelinverkkoihin.
Kuva 5. Alkuperäinen koodiherätteinen lineaariprediktio (CELP) koodekin lohko-kaavio. VQ-koodikirjan herätevektorit suodatetaan LPC ja LTP käänteissuotimilla. Alkuperäisen puhesignaalin ja suodatuksen jäännössignaalin erotus käsitellään painotussuotimella (auditoorinen suodatus). Pienemmän neliösumman virhe-kriteerin mukaan valitaan koodikirjan ehdokkaista parhaiten sopiva VQ-heräte-vektori. [1]
CELP:n suosiosta huolimatta, se ei ole mitenkään täydellinen. CELP käyttää verraten yksinkertaista puheentuottomallia (esitetty kuvassa 4). Tarkempi malli on kuvassa 6, jota käytetään glottaali koodauksessa. Mikäli huulten heijastukset sekä äänihuulten "glottis-pulssit" saadaan poistettua puhesignaalista, LPC mallintaa ääniväylää huomattavasti tehokkaammin. Glottali koodaus on osoittautunut lupaavaksi mene-telmäksi 4-5 kbit/s bittinopeuksille. [18]
Kuva 6. Glottaali koodauksessa käytetty puheentuottomalli. [18]
Puhesignaalin granulaariesitys tarkoittaa signaalin jakamista
peräkkäisiin palasiin ("grains"). Pala voi olla esim. perustaajuuden
mittainen. Koska soinnilliset äänteet pysyvät stabiilina
useamman jakson aikana, voidaan samaa joksoa toistaa. Kun äänne
muuttuu, siirrytään interpoloinnilla seuraavaan palaan. Aaltomuoto
interpolointi (WI tai PWI), joka on granulaari koodaus menetelmä,
käyttää paloja sekä nopeiden muutosten (jakson pituuden
mittaisia) että hitaiden muutosten (amplitudin vaihte-luiden) kuvaamiseen.
WI on vahava ehdokas uudeksi 2,4 kbit/s "US Federal Standardi":ksi. [19]
Sinisignaalin käsittelyyn perustuvat
puhekoodekit
Aika-taajuus interpolointi (TFI) muistuttaa harmoonista koodausta, sillä
erolla että TFI käyttää lyhyen aikaikkunan Fourier
muunnosta, vaihtuvan mittaisilla päällek-käisillä
ikkunoilla. Informaation jakautuminen aika- ja taajuusalueen kesken ohjaa
ikkunan pituutta. [20] Variantti samasta menetelmästä on sinimunnos
koodaus (STC) [19]
Menestyksekkäin uusista puheenkoodaus menetelmistä on MBE (Multi-Band Excitation). INMARTSAT-M järjestelmässä otetaan käyttöön paranneltua MBE:ia (IMBE). Puhesignaali jaetaan ei-päällekkäisiin taajuuskaistoihin (14 kappaletta) ja jokainen kaista koodataan V/UV päätöksen mukaan. Soinnillisille kaistoille sijoi-tetaan harmooninen (siniääni) ja soinnittomille kapeakaistainen kohina. [21], [22]
Viimeisten vuosien aikana puheenkoodaus on keskittynyt CELP-algoritmin jatko-kehittelyyn. Tämä on johtunut lähinnä matkapuhelin valmistajien painostuksesta saada nopeasti aikaan uusia entistä parempia koodekkeja. Valitettavasti CELP ei sovellu bittinopeuksille alle 4 kbit/s. Erittäin alhaisille nopeuksille soveltuu paremmin esim. MBE ja glottaali koodaus, erityisesti nais- sekä lasten äänten kohdalta. Myös uudet laskenta menetelmät tulevat käyttöön, kuten neuroverkot, aallokemuunnokset ja auditooriset mallit.
Laajentamalla puhekaistaa laatu paranisi huomattavasti, mutta tällä hetkellä vain ISDN tukee laajakaistapuhetta PSTN:ssä. Puhelaadun mittauksissa ollaan ottamassa laajemmin käyttöön myös objektiivisia mittausjärjestelmiä.
Johdannossa mainittiin, että puhekoodekkien luokituskriteerit ovat puutteelliset. Tässä on luotu puheenkoodaus menetelmien luokittelu (taulukko 2), joka perustuu viit-teeseen [23]. Useamman algoritmin voisi mahdollisesti sijoittaa "Abstraktit Algoritmit" kohdan alle.
Aika-alueen Taajuusalueen Fysikaalinen Abstraktit
Koodaus Koodaus Mallintaminen Algoritmit
PCM, APCM Kanava vokoodaus Artikulatoorinen Homomorfinen
vokoodaus vokoodaus
DPCM, DM, NFC Vaihe vokoodaus Glottaali koodaus VQ
ADPCM Alikaista koodaus Mozer vokoodaus
APC Harmoni koodaus
Puheen tunnistus
ja synteesi
Formantti vokoodaus
Segementti ATC, STC
vokoodaus
Granulaari koodaus FDHS
TDHS MBE
LPC,
CELP
Wavelet muunnos
koodaus
TFI
Taulukko 2. Puheenkoodaus algoritmien luokittelu, perustuen viitteeseen [23].
[1] P. Haavisto, J. Vainio, K. Järvinen, Nokia Speech Coding Seminar, Helsinki 25. Lokakuuta 1994, Nokia Tutkimuskeskus.
[2] N.S. Jayant, "High-Quality Coding of Telephone Speech and Wideband Audio," IEEE Communications Magazine, s. 10-20, Tammikuu 1990.
[3] L.R. Rabiner & R.W. Schafer, "Digital Processing of Speech Signals", Prentice-Hall, 1978.
[4] D. O'Shaughnessy, "Speech Communication: Human and Machine," Addison- Wesley Publishing Company, New York, 1987.
[5] Suositus GSM 6.41 "Discontinuous transmission (DTX) for half rate speech traffic channels", versio 4.0.0, ETSI / TC-SMG, Maaliskuu 1995.
[6] Suositus GSM 6.42 "Voice Activity Detector (VAD) for half rate speech traffic channels", versio 4.4.0, ETSI / TC-SMG, Maaliskuu 1995.
[7] J.-H. Chen & A. Gersho, "Adaptive Postfiltering for Quality Enhancement of Coded Speech", IEEE Trans. on Speech and Audio Processing, vol. 3, numero 1, s. 59-70, Tammikuu 1995.
[8] U. Laine, M. Karjalainen, T. Altosaar, "Warped Linear Prediction (WLP) in Speech Coding and Audio Processing", IEEE, 1994.
[9] D. Sen, D.H. Irving, W.H. Holmes, "Use of an Auditory Model to Improve Speech Coders", Proc. of ICASSP-93, s. II- 411-414, 1993.
[10] Suositus GSM 6.20 "Half rate speech transcoding", versio 4.0.0, ETSI / TC- SMG, Maaliskuu 1995.
[11] Y. Hitata & S. Nakagawa, "A 100 bit/s Speech Coding using a Speech Recogntion Technique", Proc. of Eurospeech '89, s. 290-293, 1989.
[12] S. Roucos, R.M. Schwartz, J. Makhoul, "A Segment Vocoder at 150 b/s", Proc. of ICASSP-83, s. 61-64, 1983.
[13] A.V. McCree, T.P. Barnwell III, "A Mixed Excitation LPC Vocoder for Low Bit Rate Speech Coding", IEEE Trans. on Speech and Audio Processing, vol. 3, numero 4, s. 242-249, Heinäkuu 1995.
[14] M.R. Schroeder & B.S. Atal, "Code-Excited Linear Prediction (CELP): High- quality Speech at Very Low Bit Rates", IEEE, 1985.
[15] R. Salami, C. Laflamme, J.-P. Adoul, " 8 kbit/s ACELP Coding of Speech with 10 ms Speech-frame: A Candidate for CCITT Standardization", Proc. of ICASSP-94, s. II- 97-100, 1994.
[16] S. Miki, K. Mano..., "A Pitch Synchronous Innovation CELP (PSI-CELP) Coder for 2-4 kbit/s", Proc. of ICASSP-94, s. II- 113-116, 1994.
[17] M. Johnson & T. Taniguchi, "Low-Complexity Multi-Mode VXC Using Multi-Stage Optimization and Mode Selection", Proc. of ICASSP-91, s. 221- 224, 1991.
[18] P. Alku, "An Automatic Inverse Filtering Method for the Analysis of Glottal Waveforms" Väitöskirja, Teknillinen Korkeakoulu, Akustiikan ja Äänenekäsittelyn laboratorio, Espoo, 1992.
[19] M.A. Kohler, L.M. Supplee, T.E. Tremain, "Progress Towards a New Government Standard 2400 bps Voice Coder", Proc. of ICASSP-95, s. 488- 491, 1995.
[20] Y. Shoham, "High-Quality Speech Coding at 2.4 kbps Based on Time- Frequency Interpolation", Proc. of Eurospeech'93, s. 741-744, 1993.
[21] J.C. Hardwick & J.S. Lim, "The Application of the IMBE Speech Coder to Mobile Communications", Proc. of ICASSP-91, s. 249-252, 1991.
[22] A. Das & A. Gersho, "Variable Dimension Spectral Coding of Speech at 2400 bps and Below with Phonetic Classification", Proc. of ICASSP-95, s. 492- 495, 1995.
[23] J.O. Smith III, "Viewpoints on the History of Digital Synthesis", Proc. of ICMC 1991.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}